Products Outline
Cancer gene mutation detection
We aim to provide cancer gene mutation detection services for hospitals, clinics, and high-end physical examination centers. Based on our gene-level diagnosis, which includes annotation of cancer driver gene mutation sites, and our recommendation of drugs and therapies, a medical doctor can devise the most appropriate course of therapy and treatment for his or her patients. We also offer non-invasive cancer screening using blood samples (liquid biopsy), to detect signs of early stage cancer for otherwise healthy individuals.
Features
- Early Detection
Our liquid biopsy tests allow us to screen for early signs of cancer and to derive a comprehensive list of risk factors. This is achieved through the detection and identification of cell mutations before any symptoms appear. With early detection, preventative measures can be undertaken in order to greatly reduce the associated cancer risks.
- Accurate Diagnosis
Through genetic screening of cancerous tissue, we can generate an exhaustive view of the gene mutation spectrum. Combining this knowledge with existing clinical results from targeted cancer drugs and therapies, allows us to recommend an individualized treatment plan for each patient.
- Prognosis Monitoring
Monitoring of patients via periodic genetic screening allows us to identify changes before and after treatment, as well as assess treatment efficacy, detect drug-resistant mutations and estimate the risk of relapse.
Advantages
- Personalized Plan
Due to the high variability in genetic mutation in even specific types of cancers, it is often difficult to find a treatment that works for all afflicted patients. Using our comprehensive DNA mutation database and target drug database, we can design treatment plans tailor-made to the patient’s individual needs.
- Atraumatic Sampling
For patients without collected pathological tissues, and those looking for preventive screening or post-operative monitoring (where cancer tissues are not available), we can make use of peripheral blood in place of a tissue sample for analysis.
- Efficient Detection
We currently possess a proprietary technology for detecting cancer DNA from patients’ peripheral blood. Our method of cancer DNA detection is very sensitive, significantly reducing the possibility of false negatives, and allowing us to achieve the high-accuracy requirements for early cancer detection and progression monitoring.
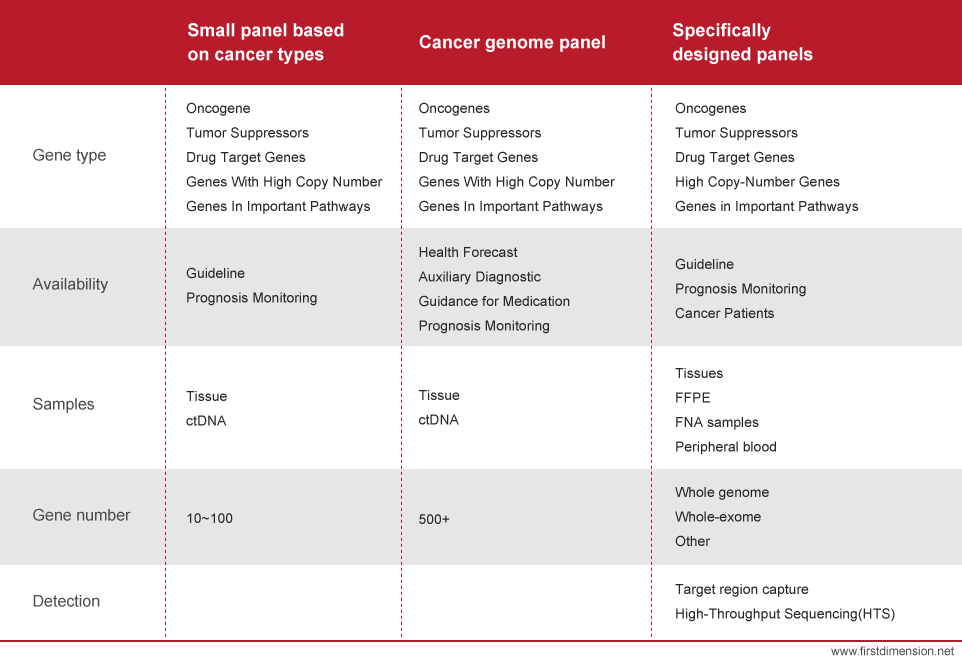
Product list
Sample Processing Procedure
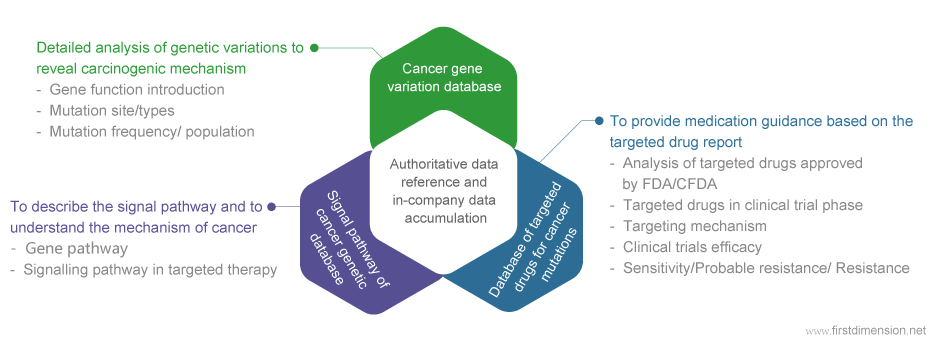
Bioinformatics software and database
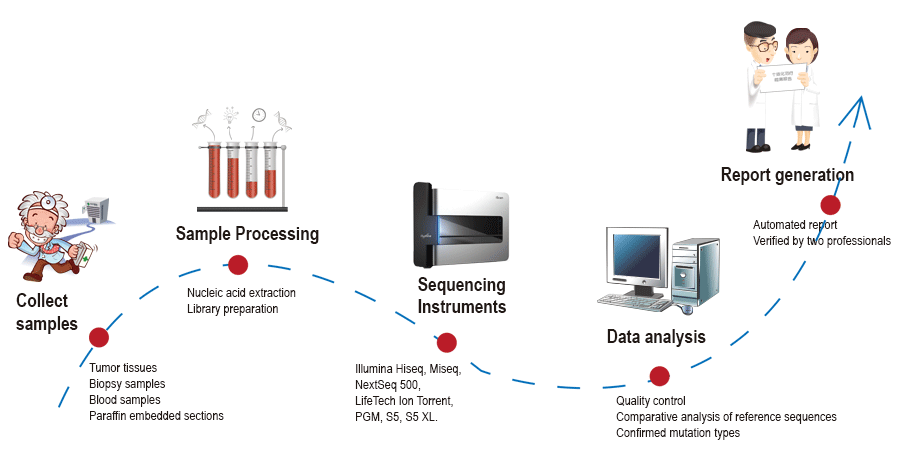
We provide an integrated solution for cancer gene mutation detection. Our services begin with the processing of raw sequence data, and end with the generation of clinically meaningful reports, including appropriate therapeutic drug recommendations.
Our software product features DNA sequence analysis, mutation identification, variation annotation, and targeted drug selection. The raw data can come from several sequencing platforms, including second generation sequencers from Illumina, and LifeTech. Our products can be applied to all solid tumors and hematologic malignancies, including, but not limited to: lung cancer, stomach cancer, liver cancer, breast cancer, colorectal cancer, lymphoma and leukemia.
Database products include: cancer driver gene mutation database, gene targeted drug database and signaling pathways database. Our database provides original scientific literature in both English and Chinese. By keeping track of many public and private resources and regularly updating our data, we aim to ensure that our collection of information is accurate and comprehensive.
Function
- Automated Analysis
We have developed a collection of highly precise analysis procedures, the FD-toolkit. We can detect cancerous variations including SNV (single nucleotide variations), Indels (insertions / deletions), SV (structural variations including translocations), and CNV (copy number variations).
- Comprehensive Interpretation
First Dimension generates and maintains a comprehensive database for cancer mutations. Our data is obtained through the curation of external databases and literatures such as GenBank, COSMIC, MyCancerGenome, PGKB, Drug Bank, ClinVar, and published clinical trials. We have a medical informatics department whose primary focus is the analysis of scientific literature and the entry of data into our database. By using this comprehensive database, we can connect a person’s cancerous mutations to the best existing drugs in the world. Thus, we ensure our drug and therapy recommendations are uniquely tailored to each individual patient.
Advantages
- High-speed
Our supercomputer allows us to process sequenced data with speeds of up to 1 teraflop. We can complete the processing of NGS data, at 2000X coverage, for more than 500 driver genes in 12 hours. For additional convenience, you can upload your sequencing data from your local machine, or network, and obtain clinical reports from the cloud.
- Self-developed Software
Many of our pipelines are developed internally. We can use the best pipeline for your data from different panels or from different sequencers.
- Effective
With our cancer gene database and targeted drug database, we can provide a list of targeted drugs based on DNA variants. Our customers will be able to access annotations of all key variants online and can search our database at no additional cost.
Super Computers
As of November 2015, First Dimension now possesses its own computer cluster which contains 720 CPUs and 400 terabytes of storage space. This gives us the ability to process the whole-exome sequences of one hundred human samples in a single day, and also allows us to employ our wide variety of data mining tools to uncover invaluable information buried deep within samples.
We have distinct pipelines for different sample types, DNA capturing methods, library constructions, and for sequences coming from different types of sequencers. It is also possible for us to custom-design a special data analysis pipeline for clients, and will save and back up data for clients for extended periods of time.
Data analysis work flow